
Lambda-Architektur
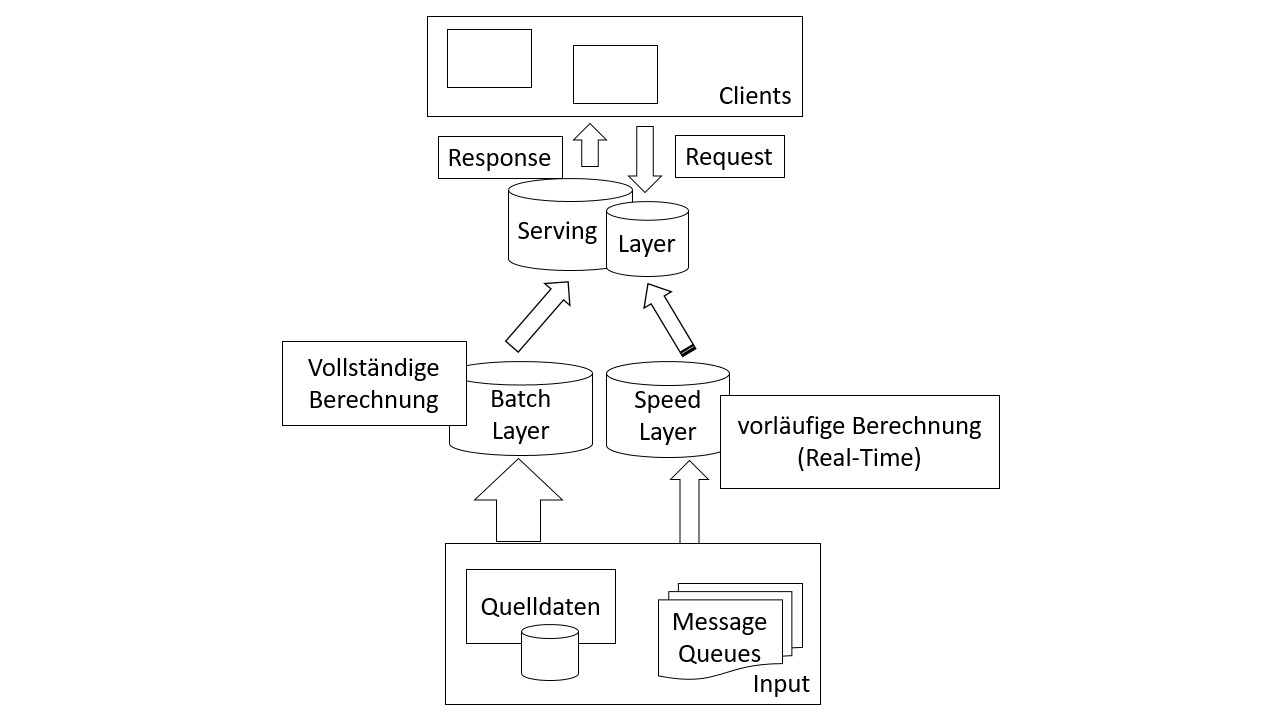
Eine Lambda-Architektur beschreibt einen Systemaufbau aus drei Bereichen, den sogenannten Layern, bestehend aus Batch Layer, Speed Layer und Serving Layer.
Die Architektur wurde von Nathan Marz entwickelt und gehört in den Bereich der sogenannten Big Data Technologien.
Eine Lambda-Architektur verwendet unterschiedliche Technologien zur Verarbeitung der riesigen Datenmengen. In den einzelnen Layern kommen spezialisierte Systeme, wie zum Besipiel Apache Hadoop, zum Einsatz, die für die jeweilige Aufgabe optimiert werden.
Einsatzbereich der Lambda-Architektur
Mit der Lambda-Architektur lassen sich riesige Datenmengen in relativ kurzer Zeit speichern und verarbeiten. Das Verarbeitungsprinzip leitet sich aus der funktionalen Programmierung ab, in der Daten nie verändert, sondern lediglich Kopien erzeugt und gespeichert werden.
Ausgehend von einer unveränderbaren Masterkopie werden die Datenverarbeitungsprozesse durchgeführt. Jede Änderung an einem Datensatz führt zur Speicherung einer neuen „Kopie“, eine Änderung (Update) wie es bei relationalen Datenbanksystemen üblich ist, gibt es nicht. Änderungen erzeugen somit Bewegungsdaten und können als Faktum angesehen werden, das zu einem bestimmten Zeitpunkt den aktuellen Zustand beschreibt oder beschrieben hat.
Die eigentlichen Informationen werden aus den einzelnen Fakten unmittelbar berechnet. Dieses Vorgehen entkoppelt die ermittelten Informationen von den vorhandenen Daten bzw. Fakten.
Die drei Ebenen der Lambda-Architektur
In der Lambda-Architektur gibt es drei sich ergänzende Layer, die auf einen Verarbeitungsprozess bzw. einen Aufgabenbereich spezialisiert sind. Wie in der Abbildung zu sehen, können die Daten über getrennte Wege (Batch Layer oder Speed Layer) über den Serving Layer bereitgestellt werden.
Batch Layer - Datenvorberechnung
Der Batch Layer verfügt über ein redundantes, verteiltes Verarbeitungssystem, in dem sehr große Datenmengen gleichzeitig verarbeitet und berechnet werden. Mit zunehmender Datenmenge erhöht sich auch die Laufzeit der Datenverarbeitung und kann mitunter mehrere Stunden umfassen. Bei der Berechnung wird auf Genauigkeit und Vollständigkeit geachtet.
Speed Layer - Lückenschließer
Im Speed Layer werden Echtzeit Ansichten der neuesten Daten berechnet und für externe Systeme zur Verfügung gestellt. Die Genauigkeit und Vollständigkeit spielt eine nachrangige Rolle. Ziel ist es die Latenzzeit des Batch Layers auszugleichen und eine vorläufige Datensicht bereitzustellen. Sind die Berechnungen im Batch Layer abgeschlossen, werden diese unmittelbar in den Speed Layer integriert.
Serving Layer - Datenlieferant
Die Ergebnisse des Batch und Speed Layers werden im Serving Layer gespeichert. Der Serving Layer ermöglicht die Bedienung von Ad-hoc Anfragen durch vorberechnete Datensichten oder aus dem vorgelagerten Verarbeitungsprozess.
Technologien in der Lambda-Architektur
Eine Lambda-Architektur verwendet unterschiedliche Technologien zur Verarbeitung der riesigen Datenmengen. In den einzelnen Layern kommen spezialisierte Systeme zum Einsatz, die für die jeweilige Aufgabe optimiert werden.
Im Batch Layer gilt Apache Hadoop quasi als Standard. Es ermöglicht eine parallele, verteilte und zuverlässige Berechnung hochfrequenter Datenmengen.
Der Speed Layer setzt auf Stream-Verarbeitungstechnologien wie Apache Storm oder Apache Spark.
Die Datenbereitstellung im Serving Layer erfolgt u. a. über dedizierte Datenbanken wie Apache Cassandra oder Apache HBase sowie Apache Hive und Elasticsearch.
Lambda-Architektur – Vorteile und Nachteile
Die Lambda-Architektur bietet zahlreiche Vorteile, hat jedoch auch einige Nachteile. Die folgenden Punkte geben eine Übersicht:
Lambda-Architektur – Vorteile der Lambda-Architektur
Die Vorteile der Lambda-Architektur lassen sich wie folgt zusammenfassen:
- Fehlertoleranz: Durch die Batch-Schicht können historische Daten erneut verarbeitet werden, was bei fehlerhaften Berechnungen nützlich ist.
- Skalierbarkeit: Die Architektur kann mit wachsenden Datenmengen problemlos umgehen.
- Flexibilität: Sowohl Echtzeit- als auch Batch-Datenverarbeitung sind möglich, was vielseitige Anwendungsmöglichkeiten schafft.
Lambda-Architektur – Nachteile der Lambda-Architektur
Trotz ihrer Vorteile hat die Lambda-Architektur auch einige Nachteile:
- Komplexität: Die Pflege und Synchronisation von zwei Verarbeitungspfaden (Batch und Speed) ist aufwändig.
- Kosten: Die Infrastruktur für die parallele Verarbeitung kann kostspielig sein.
- Latenz: Batch-Verarbeitung kann zu Verzögerungen führen, bis alle Daten integriert sind.
Lambda-Architektur – Definition & Erklärung – Zusammenfassung
Im Zusammenhang mit dem Lexikoneintrag Lambda-Architektur sollte man sich folgende Punkte merken:
- In der Lambda-Architektur können historische und aktuelle Daten gleichzeitig analysiert werden.
- Die Lambda-Architektur ist flexibel und kann mit großen Datenmengen umgehen.
- Die Lambda-Architektur erlaubt Batch-Schichten, Fehler zu korrigieren und Daten erneut zu verarbeiten.